
Your server doesn't usually fail at a convenient time. It stops on a Monday morning when staff are logging in, the accounts package won't open, shared files disappear, and everyone stands around waiting for someone in IT to “sort it”. At that point, the server isn't a piece of infrastructure. It's the thing stopping your business from invoicing, shipping, answering customers, or getting paid.
That's why Windows Server management matters. It isn't back-room housekeeping. It's operational control. If your servers handle identity, file access, line-of-business applications, printing, backups, or virtual machines, weak management creates direct business risk. Strong management protects continuity, keeps users productive, and gives you fewer nasty surprises.
For many East Midlands businesses, the challenge isn't whether they have servers. It's whether those servers are being managed deliberately or just tolerated until something breaks. There's a big difference. The businesses that stay stable treat server management like fleet maintenance on delivery vehicles. You don't wait for a van to lose a wheel on the A46 before you think about servicing. You inspect it, maintain it, and replace parts before downtime hits revenue.
Why Effective Server Management is Crucial for Your Business
If your team relies on a server for logins, shared folders, applications, or reporting, then poor management has a knock-on effect across the whole business. One missed patch can leave a security gap. One failed backup can turn a simple restore into a major incident. One overloaded host can slow down every department at once.
That's why Windows Server management should be treated as part of business governance, not just IT support. It covers how your servers are configured, updated, monitored, protected, and recovered. Done properly, it reduces disruption and gives management better control over risk.
A useful way to think about it is this. Your servers are the stockroom, switchboard, filing cabinet, and gatekeeper of your business all rolled into one. If the stockroom is disorganised, the switchboard is unreliable, and the gatekeeper forgets who should get in, the whole operation suffers.
Practical rule: If server downtime would stop staff working, then server management belongs on the leadership agenda, not at the bottom of an IT task list.
Modern server operations also sit inside wider infrastructure planning. If you want a clearer picture of how that fits into your overall estate, it helps to understand IT infrastructure management in business terms. The point is simple. Servers don't exist in isolation. They affect security, productivity, compliance, and cost.
The businesses that struggle most usually fall into one of two camps. They either leave one overworked internal person to juggle everything, or they assume that because the server is still running, it must be fine. Neither approach is disciplined enough for a business that depends on digital systems every day.
The Complete Windows Server Management Lifecycle
Windows Server management isn't one task. It's a repeating lifecycle. Treat it like maintaining a critical company vehicle. Buying it is only the start. You still need servicing, inspections, fuel checks, repairs, security, and a plan for what happens if it comes off the road.
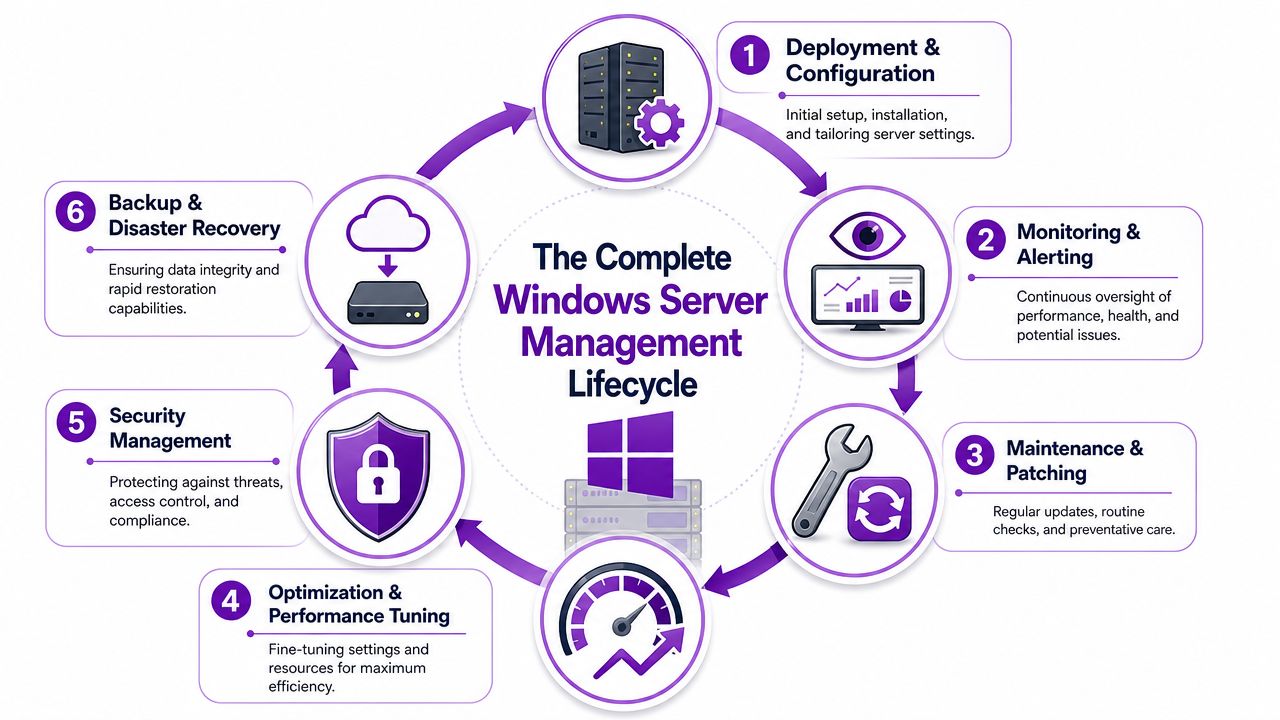
Deployment and provisioning
Good management starts before the server goes live. Poor decisions at deployment create years of unnecessary cost and complexity. Licensing, hardware sizing, virtual machine planning, and role separation all belong here.
Microsoft's licensing model for Windows Server Standard and Datacenter requires coverage for a minimum of 16 server cores per physical server, and Essentials is aimed at smaller environments with up to 25 users and 50 devices according to Microsoft licensing guidance summarised here. That matters because server design affects budget from day one. If you choose the wrong edition or build without growth in mind, you pay for it later.
Patching and maintenance
Patching isn't admin busywork. It's risk reduction. Every delayed update leaves systems exposed for longer than necessary and increases the chance of compatibility issues piling up.
A sensible patching process includes:
- Defined maintenance windows so updates don't collide with critical trading periods.
- Testing before broad rollout for servers running finance, production, or specialist software.
- Rollback planning so one bad patch doesn't become a full outage.
- Clear ownership because patches that belong to “everyone” usually belong to no one.
Monitoring and alerting
Most server problems don't begin as disasters. They start as warning signs. Disk space creeps up. Memory pressure builds. Services restart unexpectedly. Event logs fill with errors no one reads.
That's why monitoring needs to do more than produce graphs. It should tell your team what's normal, what's drifting, and what needs action now. If your only alert is a user ringing to say they can't log in, your monitoring is already late.
The first sign of a server issue shouldn't come from your receptionist.
Backup and recovery
Backups matter only if you can restore from them. Plenty of firms think they're protected because backup software says “successful”, then discover during an incident that the restore process is broken, incomplete, or too slow for the business.
Use this simple standard:
| Lifecycle area | What good looks like | Business reason |
|---|---|---|
| Backup jobs | Checked routinely | Failed jobs don’t fix themselves |
| Restore testing | Performed regularly | Recovery confidence matters more than backup theory |
| Recovery priorities | Agreed with management | Not every system needs the same response |
| Off-site protection | Included where appropriate | Local incidents can affect local backups too |
Security and identity control
Servers often hold the keys to the estate through Active Directory, file permissions, service accounts, and administrative roles. If access control is messy, your security posture is weak even if you've bought good tools.
Focus on:
- Least-privilege access so staff and suppliers only get what they need.
- Administrative separation to reduce the impact of compromised accounts.
- Group Policy discipline because inconsistent settings create avoidable risk.
- Documented decommissioning so old accounts, servers, and shares don't linger.
Disaster recovery and review
Disaster recovery is what happens when backup alone isn't enough. If a host fails, a site is unavailable, or a critical application won't start, your team needs a rehearsed response. Not a guess.
The final part of the lifecycle is review. Every outage, near miss, failed update, or storage scare should improve the next cycle. If it doesn't, you're repeating effort rather than building resilience.
Essential Tools and Microsoft Integrations
The best Windows Server management setups use a toolset, not a single silver bullet. Different tools solve different operational problems. The trick is choosing a stack that matches how your business runs, rather than bolting on products because they sound impressive.
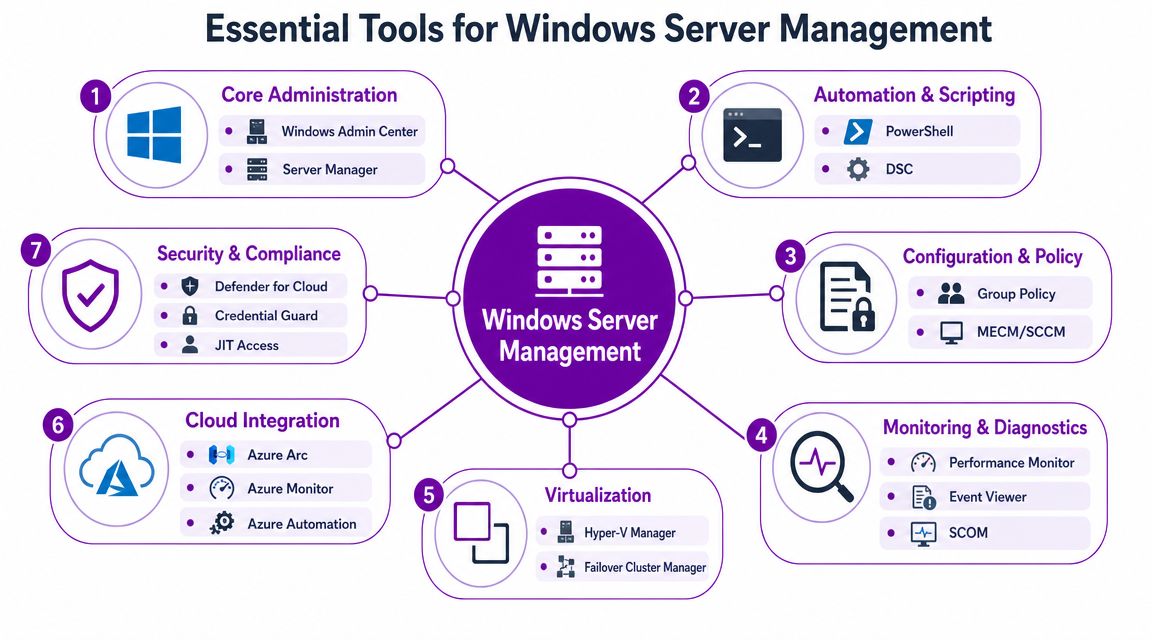
Core administration and control
For day-to-day administration, Windows Admin Center and Server Manager give IT teams direct control over roles, certificates, storage, services, and local configuration. Windows Admin Center is especially useful because it brings multiple management tasks into one browser-based experience rather than forcing admins to jump between separate consoles.
That shift matters. Server management used to be far more fragmented. Modern administration is moving towards centralised oversight, which is better for consistency and faster for troubleshooting.
Tools in this group usually cover:
- Windows Admin Center for practical server administration
- Server Manager for role-based management
- PowerShell for repeatable tasks and automation
- Desired State Configuration where consistency needs to be enforced
Policy, configuration, and endpoint alignment
Servers don't live in a vacuum. They sit inside a wider Microsoft environment that includes user devices, policies, identity, and application control. That's why Group Policy and Microsoft Endpoint Configuration Manager still matter in many estates. They help standardise settings and reduce the “every machine is different” problem that wastes support time.
For organisations increasingly blending servers with modern device management, it's also worth understanding how Microsoft Intune supports wider endpoint control. Even if Intune isn't your primary server tool, it affects how users access services, how policies are enforced, and how cleanly your estate is managed overall.
Monitoring, diagnostics, and cloud-connected management
Many businesses either gain control or lose it. Monitoring tools should help your team answer practical questions fast. Is the host healthy? Is storage tightening? Did a service fail? Is performance degrading across one VM or across the estate?
A sensible Microsoft-aligned toolkit often includes:
| Functional area | Typical tools | Why it matters |
|---|---|---|
| Diagnostics | Performance Monitor, Event Viewer | Useful for immediate investigation |
| Central monitoring | System Center Operations Manager, Azure Monitor | Better visibility across multiple systems |
| Virtualisation | Hyper-V Manager, Failover Cluster Manager | Essential where workloads are consolidated |
| Security oversight | Defender-aligned controls, privileged access measures | Keeps admin access and server posture tighter |
Microsoft also documents the broader move towards hybrid control. Azure Arc lets administrators manage physical Windows servers, Linux servers, and virtual machines even when they're outside Azure, as outlined in Microsoft's Windows Server administration overview. For UK businesses with a mixed estate, that's one of the most useful developments in server operations. It means on-premises doesn't have to mean isolated.
Good tooling should reduce admin effort and increase control. If it only adds dashboards, it's not helping.
Best Practices and Runbooks for UK SMBs
Most server estates don't fail because nobody cared. They fail because work was informal, tribal knowledge sat in one person's head, and routine tasks were handled differently every time. That's why UK SMBs need runbooks. Not fancy binders full of theory. Short, usable checklists that standardise the jobs people repeat.
A runbook is the written version of “how we do this properly here”. If someone joins, leaves, changes role, needs access, or if a server is retired, the process should be documented. That removes guesswork and reduces human error.
Build runbooks for repeatable work
Start with the tasks that carry risk when handled inconsistently:
- New starter setup including account creation, group membership, mailbox dependencies, and application access
- Leaver process covering account disablement, device recovery, forwarding, and audit trail
- Patch approval routine with timing, checks, and rollback responsibility
- Server decommissioning so old systems aren't left half-alive on the network
- Restore request handling to make sure data recovery follows an agreed path
These don't need to be long. They need to be clear. A one-page checklist that people follow beats a twenty-page document nobody reads.
Shift from reactive to predictive
Too many businesses still manage servers like they manage plumbing. They act only when something leaks. That's expensive thinking. Better Windows Server management uses telemetry to spot strain before users complain.
Microsoft's System Insights uses performance counters and log files to forecast problems such as storage exhaustion, CPU capacity issues, and network constraints, as described in this System Insights overview. That's useful because many real outages don't begin with a cyber incident. They begin with a server gradually running out of room, resources, or time.
Operational advice: Watch trends, not just thresholds. A server that's steadily heading towards trouble is often more dangerous than one brief spike.
Here's where SMBs should be practical. If you've got a small team, use predictive insight to decide when to refresh hardware, move a workload, expand storage, or tighten maintenance schedules. Don't wait for a crisis to force the decision.
Set standards your business can sustain
You don't need enterprise bureaucracy. You need discipline you can keep up with. That usually means:
- Agreeing ownership for every server and service.
- Documenting change decisions so nobody asks “who approved this?” after an incident.
- Automating routine checks where sensible.
- Reviewing logs and alerts on a schedule, not by chance.
- Testing restore processes often enough that your team trusts them.
The strongest SMB IT operations aren't always the most complex. They're the most consistent. That's what keeps support manageable and risk under control.
DIY Management Versus Outsourcing to a Partner
This is the decision most growing businesses eventually face. Keep Windows Server management fully in-house, or hand some or all of it to a managed partner. There isn't a fashionable answer. There's only the answer that fits your risk, team, and priorities.
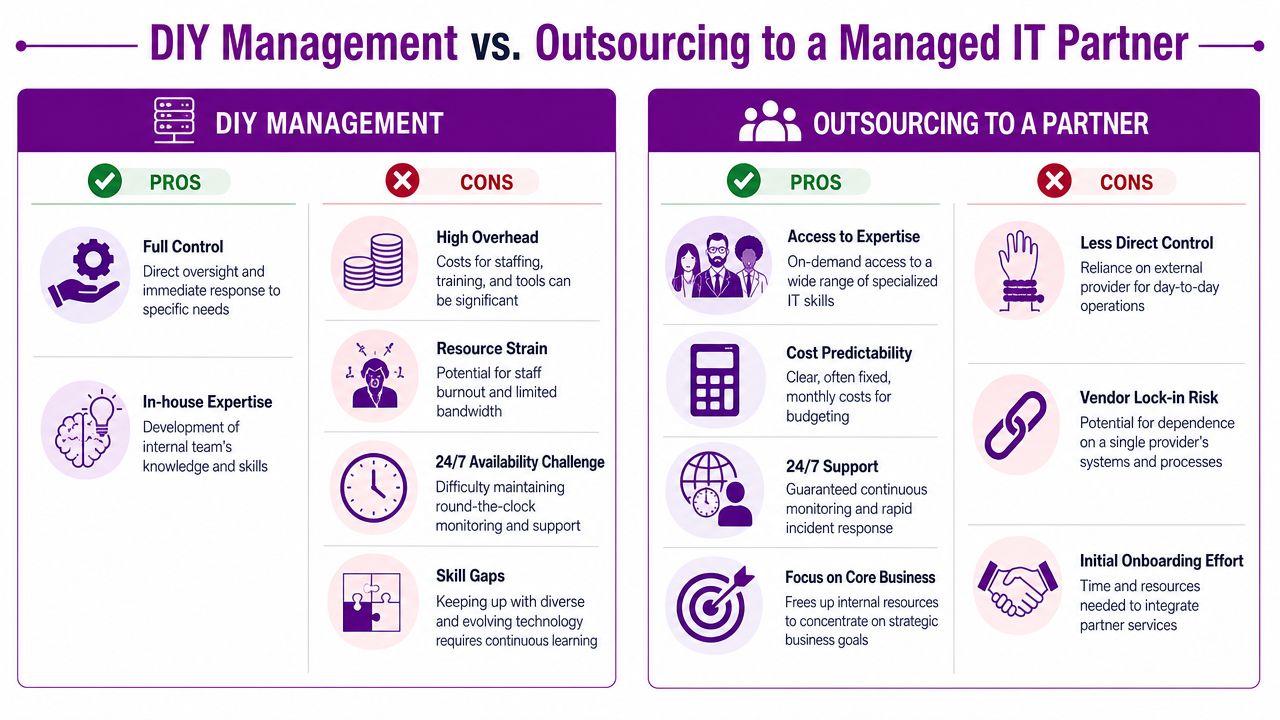
In-house management gives you direct control. If you've got capable people, documented processes, and enough cover for holidays, sickness, and project work, that can work well. The problem is that many SMBs don't have an IT team. They have one reliable person carrying too much.
Outsourcing solves a different problem. It gives you access to a wider bench of expertise, more structured monitoring, and better continuity. The trade-off is that you're relying on someone outside your payroll for day-to-day operational support.
Where DIY works well
DIY is usually sensible when:
- You have strong internal knowledge of your applications, dependencies, and business processes
- Your environment is stable and not changing rapidly
- You can cover absence without service risk
- You're prepared to invest in tools, training, and process discipline
Used properly, in-house management can be close to the business and highly responsive. Used badly, it creates a single point of failure around one person's memory and availability.
A short explainer on the wider managed model can help frame the decision:
Where outsourcing is the better call
Outsourcing is often the stronger option when the business needs resilience more than ownership theatre. If your key IT person is also dealing with support tickets, user onboarding, supplier calls, cyber issues, and infrastructure changes, they're stretched. Server management becomes reactive by default.
Use this checklist truthfully:
| Decision area | DIY question | Outsourced question |
|---|---|---|
| Coverage | Can you monitor and respond reliably when internal staff are away? | Does the provider give dependable operational cover? |
| Skills | Do you have the right depth across servers, security, backup, and virtualisation? | Can the provider prove capability in those areas? |
| Process | Are runbooks, access controls, and recovery plans documented? | Will the provider work to defined procedures and service levels? |
| Focus | Is your internal team spending too much time keeping the lights on? | Would external support free internal staff for strategic work? |
If your in-house model depends on one person never being ill, leaving, or taking holiday, it isn't a strategy. It's a vulnerability.
The right answer for many firms is hybrid. Keep strategic control in-house, outsource the operational heavy lifting, and insist on proper documentation so you don't lose visibility.
Navigating Hybrid Cloud and Server Migration
Most UK businesses aren't choosing between “all on-premises” and “all cloud”. They're dealing with a mix. Some workloads need to stay local because of latency, integration, legacy software, or control. Others are better moved because they need flexibility, remote access, or easier resilience. That's why hybrid is usually the practical route.
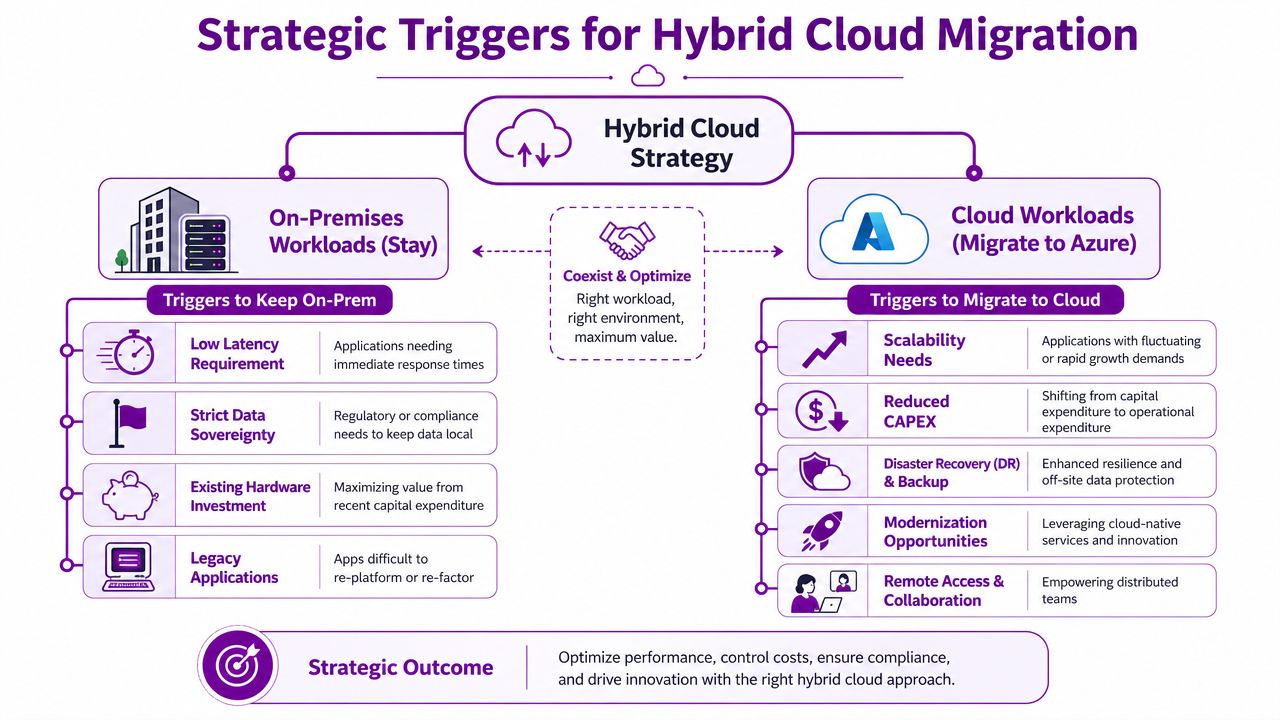
Decide by workload, not ideology
Don't migrate a server just because “cloud” sounds modern. Move workloads for business reasons. Keep them local for business reasons. The wrong migration is just as wasteful as no migration.
Typical reasons to keep a workload on-premises include:
- Low-latency requirements for systems that need immediate local response
- Data handling requirements where local control matters
- Recent hardware investment that still has value to deliver
- Legacy application dependency where replatforming would create unnecessary disruption
Reasons to migrate tend to be different. Better scalability, simpler disaster recovery options, and easier remote accessibility are common drivers. The point is to judge each workload by operational fit.
Use hybrid control to reduce complexity
A lot of managers hear “hybrid” and assume “messy”. It doesn't have to be. Microsoft's direction has been towards integrated control, and Azure Arc is a major part of that. It allows administrators to manage on-premises physical Windows servers, Linux servers, and virtual machines from the same control plane as cloud resources, which makes hybrid estates more governable rather than less.
That's valuable for organisations that can't justify a disruptive, all-at-once move. You can modernise management before you modernise every workload.
If you're planning migration activity, it also pays to follow structured data migration best practices. Most migration pain comes from poor preparation, vague ownership, and underestimating dependencies.
Make the move in stages
A sensible hybrid migration usually follows a phased approach:
- Audit the estate and identify what each server does.
- Classify workloads by business criticality, dependency, and suitability.
- Stabilise what stays so old on-premises workloads aren't neglected.
- Migrate selected services first where the benefit is clear and the risk is manageable.
- Unify management so your team isn't supporting two disconnected worlds.
If you're a startup or a growth-stage business exploring Azure as part of that journey, it can be worth checking resources that help you find Azure cloud credits. That's useful when you want to test cloud services without turning experimentation into uncontrolled spend.
Hybrid works best when it's deliberate. Keep what should stay. Move what should move. Manage both with the same operational discipline.
Your Checklist for Onboarding a Managed IT Partner
If you've decided to bring in a managed partner, the handover needs structure. A poor onboarding creates confusion, duplicated tools, unclear responsibilities, and avoidable risk. A good onboarding creates visibility fast and sets the relationship up properly.
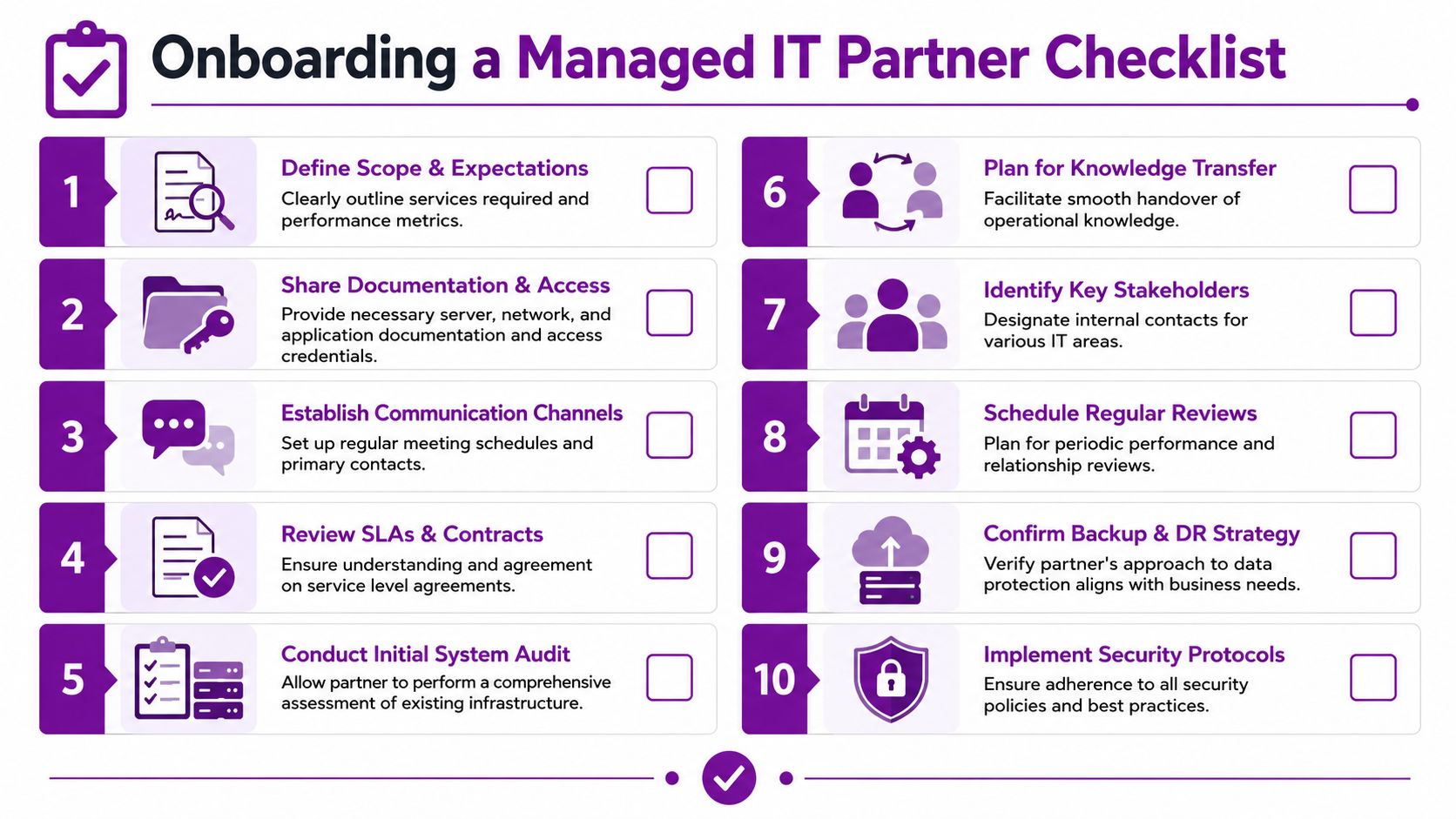
Start with scope and access
The provider can't support what they can't see. Agree the scope first. Which servers are included, which services are excluded, who owns third-party applications, and what response expectations apply to critical incidents.
Then get the basics in order:
- Access credentials for servers, hypervisors, backup systems, and admin tools
- Network and system documentation that shows what connects to what
- Named stakeholders inside your business for technical, operational, and commercial decisions
- Existing supplier details where another third party still supports part of the environment
This stage tells you a lot about the maturity of your own estate. If nobody can explain what a server does, that's a risk in itself.
Define service levels and working rhythm
Service levels need to be practical, not vague. If a file server fails at the start of the day, how quickly should the partner respond? Who gets informed? What gets escalated? What's covered out of hours?
Use a working checklist like this:
| Phase | Key Action | Your Responsibility |
|---|---|---|
| Discovery | Confirm server inventory and dependencies | Share current documentation and contacts |
| Contracting | Review SLAs and responsibilities | Approve realistic service expectations |
| Access setup | Provide admin and platform access | Ensure credentials are current and authorised |
| Tool deployment | Allow monitoring and backup configuration | Coordinate change windows if needed |
| Knowledge transfer | Explain business-critical systems | Involve the right internal people |
| Governance | Set review meetings and reporting expectations | Attend reviews and make decisions promptly |
The best onboarding is collaborative. Your provider brings process. You bring context.
Treat onboarding as a risk reduction exercise
Onboarding's purpose isn't paperwork. It's control. The partner should audit the environment, validate backups, establish monitoring, review security exposure, and flag obvious weaknesses early. If they don't, they're just inheriting your blind spots.
By the end of onboarding, you should have:
- Clear support boundaries
- Known escalation paths
- Baseline visibility
- Agreed reporting
- A documented recovery approach
That's when managed Windows Server management starts delivering value. Not when the contract is signed, but when operational ambiguity is removed.
If you want practical advice on Windows Server management, hybrid infrastructure, or fully managed support, speak to F1Group. We support organisations across the East Midlands with dependable Microsoft-focused IT services that keep systems secure, stable, and properly managed. Phone 0845 855 0000 today or send us a message.